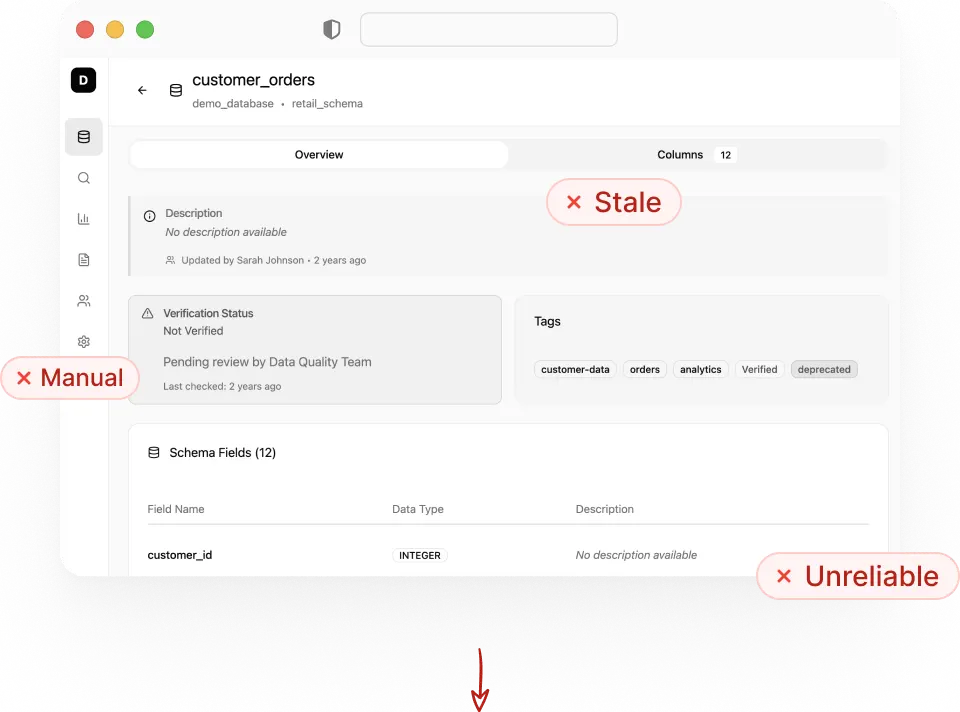
A compounding problem
Software moves fast. Data Governance does not.
When governance trails engineering, small schema changes compound into business risk. Developer velocity without data governance control is a liability for AI transformation.

Woven.dev watches for schema changes, updates metadata, alerts stakeholders, and enforces policies — automatically.







schema: https://opendapi.org/spec/0-0-1/dapi.json
title: User
description: This data model represents a customer entity.
It includes essential information about the user, such as
their identification details, contact information, and
preferences.
urn: company.users.user_entity
type: entity
owner_team_urn: company.engineering.user_management
datastores:
sources:
- urn: company.postgres.user_db
business_purposes:
- user_management
- authentication
retention_days: 3650
sinks:
- urn: company.postgres.user_db
business_purposes:
- user_management
retention_days: 365
fields:
- name: user_id
data_type: integer
is_nullable: false
description: Unique numerical identifier for the user.
This is the primary key for the user record.
data_subjects_and_categories:
- subject_urn: user
category_urn: identifier.user_id
sensitivity_level: internal
is_personal_data: true
is_direct_identifier: false
- name: full_name
data_type: string
is_nullable: false
description: The user's full name, including first and last
names.
data_subjects_and_categories:
- subject_urn: user
category_urn: name
sensitivity_level: confidential
is_personal_data: true
is_direct_identifier: true
- name: email
data_type: string
is_nullable: true
description: The user's email address.
data_subjects_and_categories:
- subject_urn: user
category_urn: contact.email
sensitivity_level: confidential
is_personal_data: true
is_direct_identifier: true
- name: created_at
data_type: timestamp
is_nullable: false
description: The timestamp indicating when the user account
was created.
data_subjects_and_categories:
- subject_urn: user
category_urn: metadata
sensitivity_level: internal
is_personal_data: false
is_direct_identifier: false
- name: updated_at
data_type: timestamp
is_nullable: false
description: The timestamp indicating when the user account
was last updated.
data_subjects_and_categories:
- subject_urn: user
category_urn: metadata
sensitivity_level: internal
is_personal_data: false
is_direct_identifier: false
primary_key:
- user_id
privacy_requirements:
dsar_access_endpoint: /dsr/access/users/{id}
dsar_deletion_endpoint: /dsr/deletion/users/{id}
context:
service: user_service
integration: sqlalchemy
rel_model_path: models/user.py
rel_doc_path: docs/user_api.md

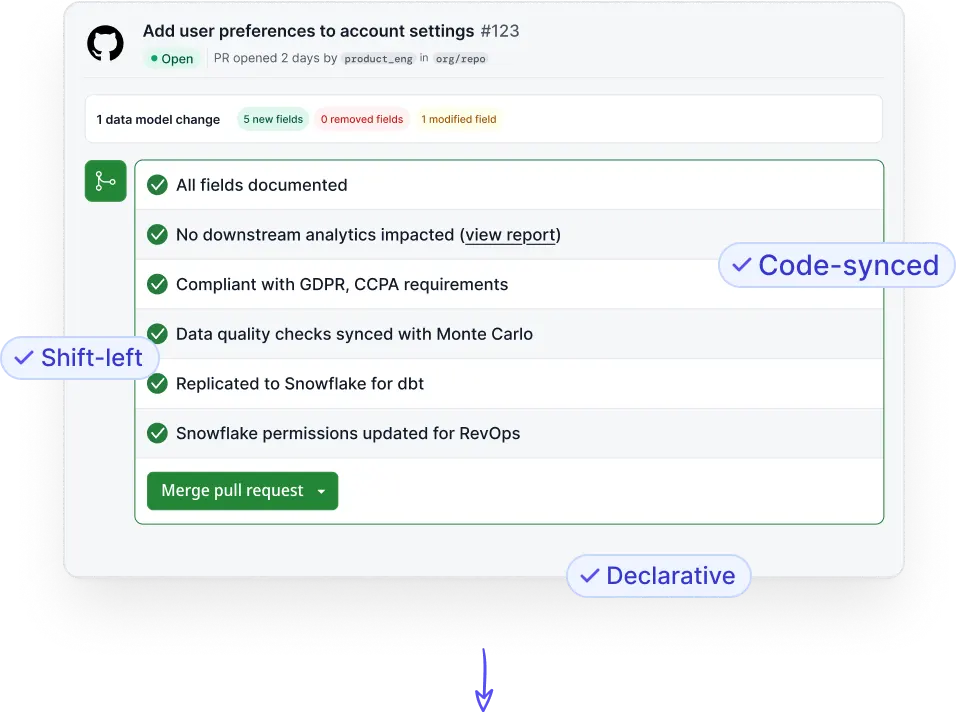
By integrating in your CI pipelines to keep metadata in-sync with your source code, Woven can enforce governance controls, automate your DataOps workflows, and streamline how engineering and data teams collaborate


Woven AI enriches updated schemas based on your metadata graph and data policies. By integrating into your existing CI pipeline, it's simple and familiar to review and commit the metadata suggestions.
See the product
Define your data policies in code or using Woven's governance portal. Each policy will appear in the developer experience as a task that must be completed before code is deployed. Find, fix, and prevent data issues before they impact production!

What workflows need to happen whenever a data model changes in code? That's what Woven automates for you! Native connectors and workflow configurations give you the power of declarative metadata. Think: Terraform for your data stack.

Change is the only constant. Woven is built to make sure your data stakeholdes and consumers know about upcoming and recent data model changes so that they can adapt. Or, use Woven to bring data consumers into the PR to ensure strong collaboration from the start.
Find, fix, and prevent data issues before merge

Metadata files update in the same PR as schema changes

Replication, masking, retention, and dbt all run automatically

Find, fix, and prevent data issues before merge
Metadata files update in the same PR as schema changes
Replication, masking, retention, and dbt all run automatically
Define and evaluate data privacy policies as part of CI so engineers can find, fix, and prevent privacy non-compliance risks prior to code being deployed.
Automate sensitivity classification, data masking, and access controls workflows to keep data safe whenever a schema changes.
Accelerate time-to-value by auto-updating your dbt analytics layer, complete with documentation and tests, whenever an upstream table changes.
Get to "AI-ready" data by design, with trust, privacy, and security powered by your enterprise's context-rich metadata graph.


